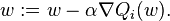In stochastic gradient descent, the true gradient is approximated by gradient at each single example.
As the algorithm sweeps through the training set, it performs the above update for each training example. Several passes can be made over the training set until the algorithm converges, if this is done, the data can be shuffled for each pass to prevent cycles.
Obviously it is faster than normal gradient descent, cause we don’t have to compute cost function over the entire data set in each iteration in case of stochastic gradinet descent.
stochasticGradientDescent in AD:
This is my implementation of Stochastic Gradient Descent in AD library, you can get it from my fork of AD.
Its type signature is
12345
stochasticGradientDescent :: (Traversable f, Fractional a, Ord a)
=> (forall s. Reifies s Tape => f (Scalar a) -> f (Reverse s a) -> Reverse s a)
-> [f (Scalar a)]
-> f a
-> [f a]
Its arguments are:
errorSingle :: (forall s. Reifies s Tape => f (Scalar a) -> f (Reverse s a) -> Reverse s a) function, that computes error in a single training sample given theta
Entire training data, you should be able to map the above errorSingle function over the training data.
and initial Theta
Example:
Here is the sample data I’m running stochasticGradientDescent on.
Its just 97 rows of samples with two columns, first column is y and the other is x
Below is our error function, a simple squared loss error function. You can introduce regularization here if you want.
1234567891011121314
errorSingle ::
forall a. (Floating a, Mode a)
=> [Scalar a]
-> [a]
-> a
errorSingle d0 theta = sqhalf $ costSingle (tail d0) theta - auto ( head d0)
where
sqhalf t = (t**2)/2
costSingle x' theta' = constant + sum (zipWith (*) coeff autox')
where
constant = head theta'
autox' = map auto x'
coeff = tail theta'
> import csv
> import numpy as np
> from sklearn import linear_model
> f = open('exampledata.txt', 'r')
> fcsv = csv.reader(f)
> d = []
> try:
> while True:
> d.append(fcsv.next())
> except:
> pass
> f.close()
> for i in range(len(d)):
> for j in range(2):
> d[i][j] = float(d[i][j])
> x = []
> y = []
> for i in range(len(d)):
> x.append(d[i][1:])
> y.append(d[i][0])
# initial learning rate eta0 = 0.001
# learning rate is constant
# regularization parameter alpha = 0.0, as we ignored reqularization
# loss function = squared_loss
# n_iter or epoch, how many times does the algorithm pass our training data.
> reg = linear_model.SGDRegressor(alpha=0.0, eta0=0.001, loss='squared_loss',n_iter=1, learning_rate='constant' )
# start training with initial theta of 0, 0
> sgd = reg.fit(x,y, coef_init=[0], intercept_init=[0])
> print [sgd.intercept_, sgd.coef_]
[array([ 0.29815173]), array([ 1.20270826])]
The only restriction we have in our implementation of stochasticGradientDescent is that we set the learning rate a default value of 0.001 and is a constant through out the algorithm.
The rest of the things like the sort of regulariztion, regularization parameter, loss function we are using, we can specify in errorSingle.
Results:
So when n_iter = 1, went through the entire data set once, so we must check 97th theta from our regression result from AD.
Similarly n_iter = 2 implies 97*2 iteration in our implementation, and etc.,